
Understanding Data Factory in a CI/CD world
For those that are unfamiliar Azure Data Factory is defined as:
…the cloud-based ETL and data integration service that allows you to create data-driven workflows for orchestrating data movement and transforming data at scale. Using Azure Data Factory, you can create and schedule data-driven workflows (called pipelines) that can ingest data from disparate data stores. You can build complex ETL processes that transform data visually with data flows or by using compute services such as Azure HDInsight Hadoop, Azure Databricks, and Azure SQL Database.
Essentially think of it as a next generation SSIS engine if you are familar with the Microsoft tech stack or think of it as an alternative to SAP Data Services or Informatica if you are familiar with those tools.
If you are familiar with those tools then you are aware that they way development is done differs from a traditional application development lifecycle. This stems from the fact that if we are traversing and transforming large amounts of data we can’t do that on our local machines nor can really do that on a VM. As such we usually push/orchestrate any changes directly in a dev/sandbox environment. This traditional works; however, things get kind of hairy when we start adding more developers. We start running into potential issues with resource constraints and issue such as conflicting schema definitions.
Full transparency Data Factory does have an answer for some of this; however, it still has its tradeoffs.
Azure Data Factory “offically” supports CI/CD; however, if you walk through this documentation take special note of this diagram:

Notice that the code flow would be:
master->adf_publish
This push is triggered by the Publish button in the Azure Data Factory Pipeline Editor. What it is really doing is consolidating ARM templates.
Here is what master would look like:
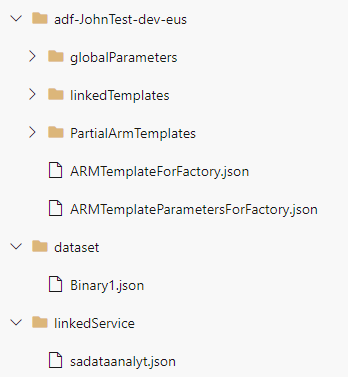
While the adf_publish branch looks like:
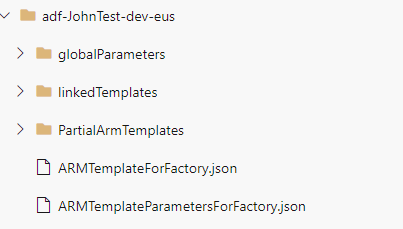
Wait what happened? My best guess is that the publish button runs some Powershell to consolidate ARM templates. Unfortunately what this translates into is that our adf_publish branch can’t merge back into master due to conflicts:

So if you have a development background this may seem very strange to you. Our master branch does not equal our publish branch? Nor can we take our publish branch and move it back into master?
By going this approach there are a few other downsides mainly:
- More likely to hit ARM Template Limitations
- 256 parameters
- 256 variables
- 800 resources (including copy count)
- 64 output values
- 24,576 characters in a template expression
- Deployment will be everything
- Does not include additional Data Factory settings like Monitoring
- Only one ARM parameter file is produced
- Access to everything in the repository
Let me stress, this approach DOES WORK. As in many things development wise there is always more then one approach. At the end of day what we are doing is deploying ARM templates, so why not do them manually?
To accomplish this a structure of repos might be created and organized such as:
- Pipelines
- DataSets
- Linked Services
- Triggers
- DataFactory and it’s dependencies
Each repository will contain just the ARM template sections that it relates to. To do this each repository can publish out of it’s main branch with it’s desired ARM templates and environment specific parameters. This may feel more natural to those who do applciation development. We can create branches/tags as needed to better evaluate and manage our releases. In addition we can also now control access at the repository level. Require special access for Linked Services, now you have it.
The trade off for this flexibility would mean:
- Multiple Repositories
- Managed Dependencies between repositories
- Still all pipelines or none
Further more another potential option would be the introduction of a repository per Pipeline. This may look like:
- Pipeline1
- Pipeline2
- Linked Services
- DataSets
- Triggers
- DataFactory and it’s Dependencies
Again a lot of the same tradeoffs as mentioned before still exist; however, now we can scope everything down to the pipeline at the repository level. Not to mention now each pipeline can adhere to it’s own development life cycle.
However even this has it’s tradeoffs:
- Even more repositories
- More likely to hit 800 resource group deployments limit
- Dependencies
- “Technically” every deployment redeploys a shell data factory
- Updating Data Factory API could be problematic
Let me stress again ANY OF THESE WAYS WORK. It’s just a matter of how a team/organization/individual wants to maintain and organize their work. Hopefully this has given a good overview on just some of the options available to you for CI/CD with Data Factory.
Discover more from John Folberth
Subscribe to get the latest posts sent to your email.